
What Is Important When It Comes to the "Inosculation" of AI with Software Engineering? (as of May 2026) - Part 1.
A series of the current landscape: an unpacking of what has transpired, what is presently unfolding, and what soon may break upon the horizon with regards to AI<>Software Engineering. Part 1.

Software engineering did not gradually absorb AI. It was abrupter than that. There is little point in rehearsing the arc from the ChatGPT release in late 2022 through the proliferation of LLMs into every corner of the field, many others have talked about that story and will continue to. What matters now is the current snapshot, weighted heavily toward the last six to twelve months. The tools change so fast that even engineers who stepped away from the conversation for even a moment of time came back to find the vocabulary, the workflows, and the reasonable expectations had all shifted. This is not catastrophism. It is simply the tempo of the moment, and it demands a particular kind of calibration before anything else can be said usefully.
Current snapshot of SOTA Models by Frontier Labs
(Understanding their priorities/incentives to make sense of what tasks their models will continue to get good at).
The first thing worth establishing is where the frontier models actually sit. And not in the abstract, but roughly task by task or groupings of tasks. Harvard coined a useful term for this: the jagged frontier. These models are sharp on some tasks and quietly unreliable on others, sometimes within the same session. The jaggedness is the point. A model that writes a well-structured algorithm can, moments later, confidently misremember an API signature (unfortunate) or lose the thread of its own reasoning mid-task. Knowing where those edges sit has become a genuine professional skill. And it’s something that you develop and polish over time as you interact with and use these models (especially in powerful “harness” like Claude Code or Codex).
# A tip on a small intervention to deal with annoying “forgetting” or “hallucinations”
# Of rather important but minute details when in long and “polluted” context windows.
# Make a command that reads important context on invocation.
# This way you “inject” that context as a reminder during the part when
# an LLM needs to generate such commands/text and not forget critical details.
<a prompt like this to your AI model>
- You seem to be forgetting details of <X, Y, Z> throughout the conversation.
- Build a simple custom skill/command that can be invoked easily in a turn.
- This skill will do something simple like “grep” on a `.md` file.
- That `.md` file will contain just enough context to prevent forgetting.
</a prompt like this to your AI model>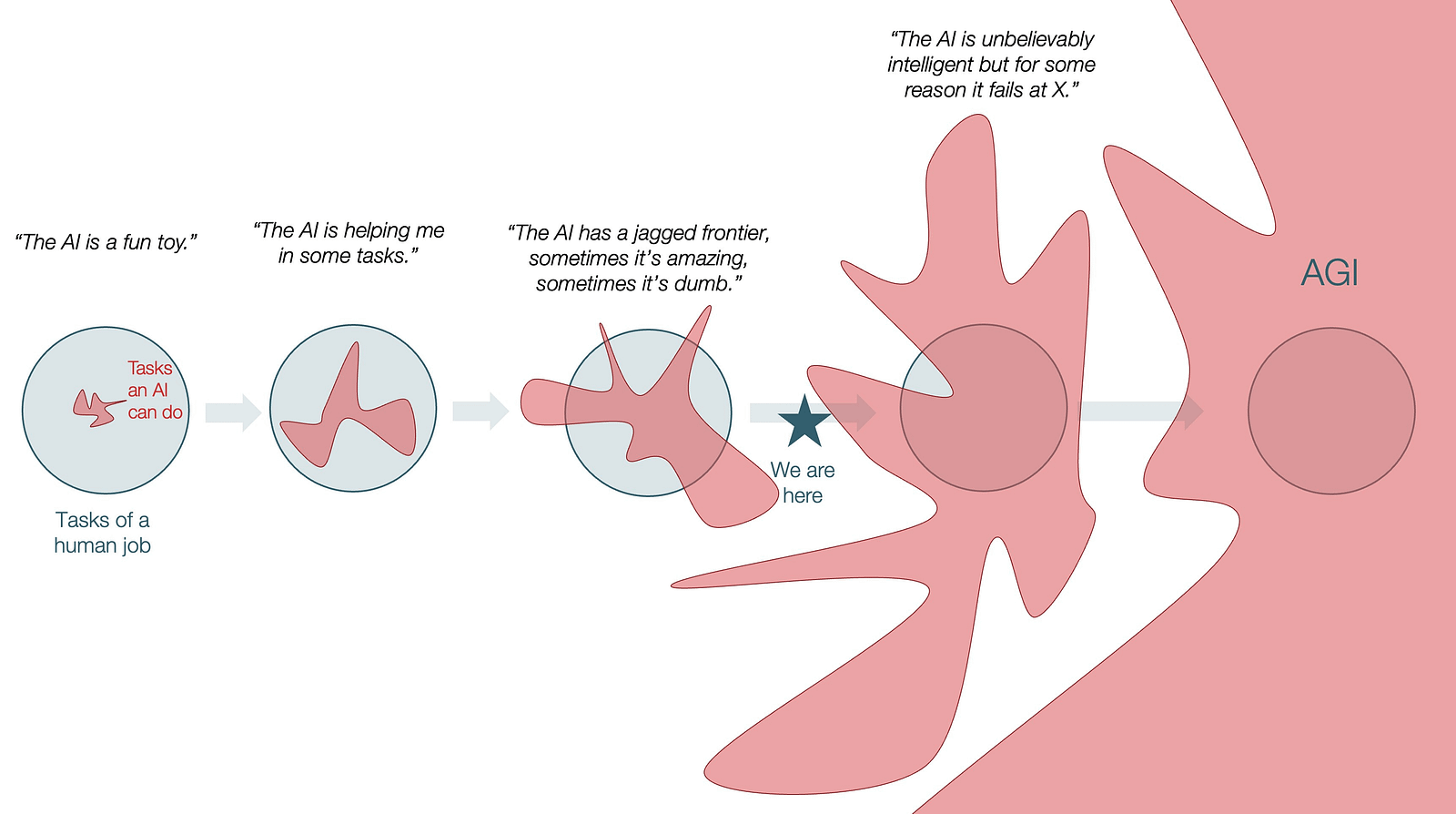
In the last 1–2 years, models are not necessarily exactly uniformly improving. They are improving in specific directions, and those directions are not accidental. The frontier labs have visibly shifted training emphasis toward agentic workflows and programming (this is obvious and doesn’t require much evidence). While the internals are a black box, the reasoning is not hard to follow. Reminds yourself that Reinforcement learning (being used in “new” forms by frontier labs) requires an environment with a reliable verifier: something that can tell the model cleanly whether it succeeded or failed. Code is a near-perfect medium for this. Tests pass or they don’t. A pull request either compiles and satisfies the reviewer’s criteria (at least objective criteria) or it doesn’t. That clean signal makes it possible to structure reward functions and run RL at scale in a way that, say, “write me a persuasive essay” simply cannot match. Creative Writing is an example of a domain that is hard to improve on.
The result is that multi-turn agentic coding (model planning, calling tools, reading output, self-correcting, and eventually solving X task) got noticeably better over the last six to twelve months. Around December 2025, it felt less like incremental improvement and more like a step change. The labs will keep pushing this direction: their revenue is heavily weighted toward engineering customers, the training data is rich and accessible, and the RL loop is clean. You don’t need an internal memo to see where the investment is going.
And why is the model being so good at programming so useful beyond just “coding”? Look at the next image to understand why.

Does this mean that “native” tool-calling in LLMs is not token efficient and not as good when it comes to quality/capabilities as the models writing code that performs the tool call itself? I definitely think so.
After all, Anthropic wrote on article on this long ago. Recall this post by Anthropic some time ago. Using this article to make a “spec”, I recall some people made some implementations of this and posted on the Claude subreddit, reporting much more token efficiency and accurate tool calling in their Claude Code workflows. Of course this applies to any SOTA model like Codex as well.
If all SOTA LLMs converge on this conclusion going forward, I think it’s good. I expect models to get much more token efficient when it comes tool calling (and hopefully more accurate/useful). Writing code is just much succincter and accurate! It just makes sense on this pivot in general.
One could go further and argue more speculative points here; things like getting models good at programming builds “model IQ” that carries over into other disciplines. That steps into the realm of cognitive science but in the domain of LLMs but is something that could probably be measured and experimented on. I can’t recall right now if such experiments do exist, but I imagine they will also have their limitations. It’s probably too early for anything definitive, but worth watching.
Another signal worth tracking is how system prompts change over time. Occasionally the frontier labs publish them; and other times, they leak. Either way, reading them carefully is quite revealing, not as a curiosity, but as a form of “archaeology” about the model and how its intended to be driven/steered. A system prompt is a record of what the labs discovered the model needed to be told, which is itself a record of how the model behaved before they told it. Watch a lab's system prompts evolve across 6 or 12 months and you are, in a roundabout way, watching the model's failure modes evolve. Simon Willison has been doing this kind of close reading for years, and it repays attention. Look at a recent system prompt change as an example.
And this next image captures another interesting point to consider about how what we are noticing how the model changes. A subtler observation worth considering, one that cuts against the instinct to treat improvement as straightforwardly good. As frontier LLMs get better, they become worse models of human error. Not human intelligence, but human error. Digest that one for a moment.
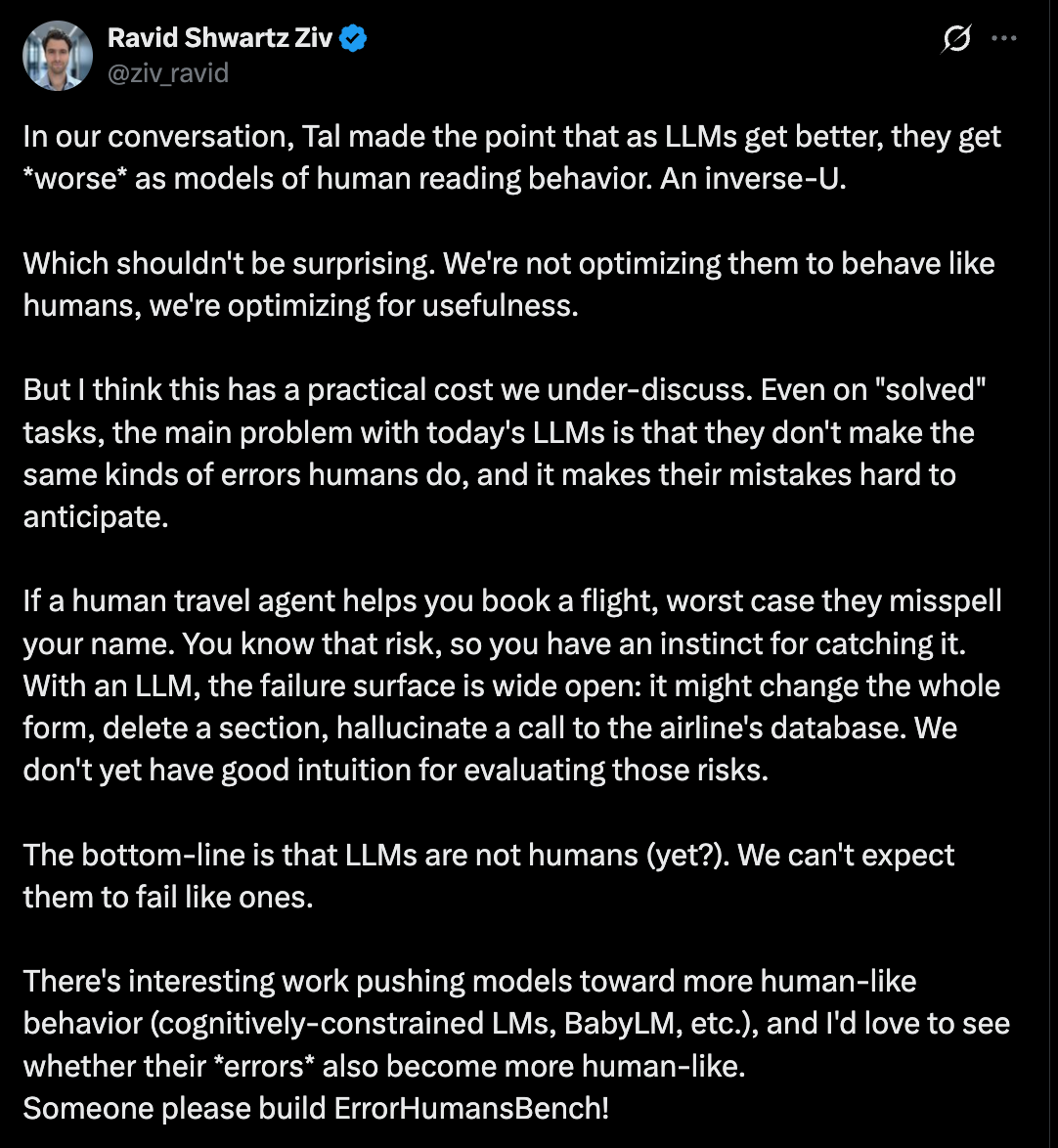
This sort of “gap” between usefulness and predictability seems to be where a lot of unpleasant surprises originate from.
With Regards to the “Tooling Layer” of Agents, CLIs, and Harnesses That Wrap the SOTA Models.
Generating code is now the cheap part. What separates good output from mediocre output is the harness around the model (tools, prompts, skills, filesystem memory, sub-agents, guardrails, context management, etc.) and workflow you hand it before it writes a single line. This is where most of the practical leverage sits in 2026, and it is also where one could argue that lots of engineers are underinvesting.
Current tools that are hot right now are the agentic CLIs like Claude Code and Codex CLI. They tend to be first-class in a literal sense that new features land there before the desktop app analogs do. Cursor-style chat interfaces are fine but somewhat overrated in my opinion when put next to these CLIs and the official apps coming directly from the frontier labs. If you have not yet driven a CLI end to end on a real workflow, I think you are missing out and you should try using these harnesses at least a few times.
MCP servers, plugins, and skills are mature enough now for daily use fortunately. They are roughly interchangeable ways to do the same kind of thing: hand the agent extra tools, prompts and context it would not otherwise have. And one shouldn’t reduce their impact. A very well written prompt that is injected at the right time in a conversation can make a big difference.
A set of common CLI plugins/”tools” worth knowing specifically:
Context7 or something similar for live, version-correct library documentation.
LSP integration for Claude Code in your language of choice (Codex does not have this yet).
Obra’s “Superpowers” if you haven’t looked at it.
Both Claude and the Codex also have their own “official” plugin marketplaces, and those are the right place to start rather than random repos people are pushing on GitHub.
There is definitely security risk in cloning random skill packages from the internet, and it is worth being cautious about what you let run inside your agent’s environment.
The mental model worth internalizing here is simple: an agent is only as good as the tools and context you give it. An agent is only as good as the tools and context you give it. Wiring together the right MCPs and skills for your stack takes time and genuine experimentation, sort of like a craft that you develop and polish over time. What might serves a Python backend team well can differ from what a TypeScript frontend team needs, and the answer rarely arrives before you get some skin in the game. The official marketplaces are a reasonable place to start. The official marketplaces from Anthropic and Codex are a good place to start though.
Out of everything I’ve covered in this article, I would say this is probably the highest-leverage habit to build. Most complaints along the lines of “the AI is bad at my codebase” are, underneath, probably some degree of “context problems”. The model is not suddenly less capable it, but rather it does not have what it needs to do the job well. Squeezing the right information out of these models is not a trivial task to do.
A practical habit here one can develop and maintain is keeping durable context in plain .md files that live in the repo. Files that are human-readable, version-controlled, and findable.
Hierarchical .md files per directory also work well for larger codebases. The file an agent reads first, CLAUDE.md or its equivalent, is load-bearing infrastructure. One stale or wrong line near the top can quietly steer everything the model produces downstream. Treat it like code, because functionally it is.
“Context engineering” (the new term that captures the nature of this well) is probably the least glamorous part of working with these models, and almost certainly the highest-leverage. The common complaint “the AI is bad at my codebase” is, more often than not, a context problem in disguise. The model has not suddenly become less capable, rather it probably does not have what it needs to do the job well.
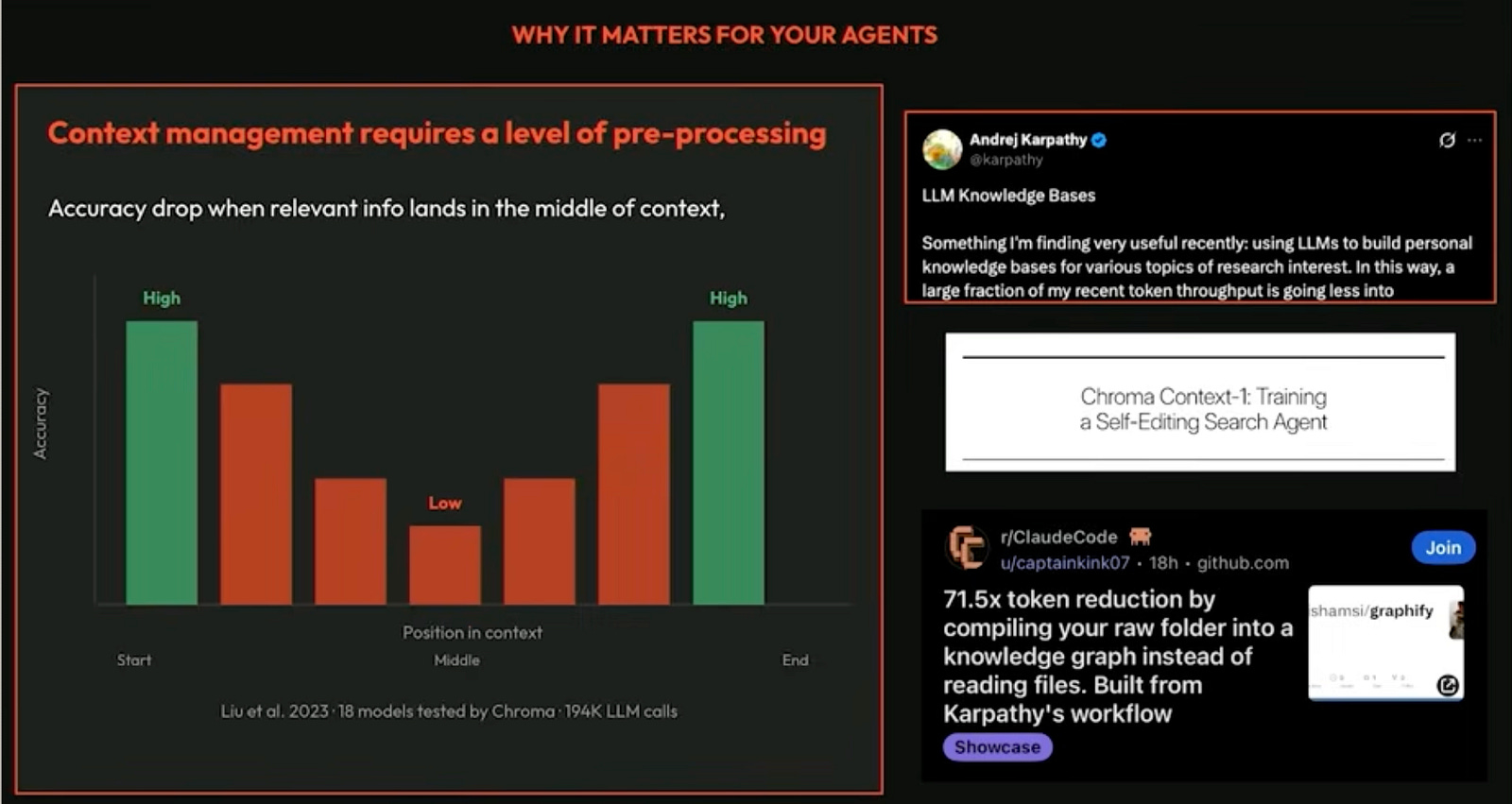
One concrete dimension of this: where information sits inside the context window matters as much as whether it is there at all. Research from Liu et al. (2023), tested across 18 models and nearly 200,000 LLM calls, found a measurable accuracy drop when relevant information lands in the middle of the context rather than near the start or end. The model is not reading your .md files the way you read a document. Position is of context in your prompt is not to be dismissed!
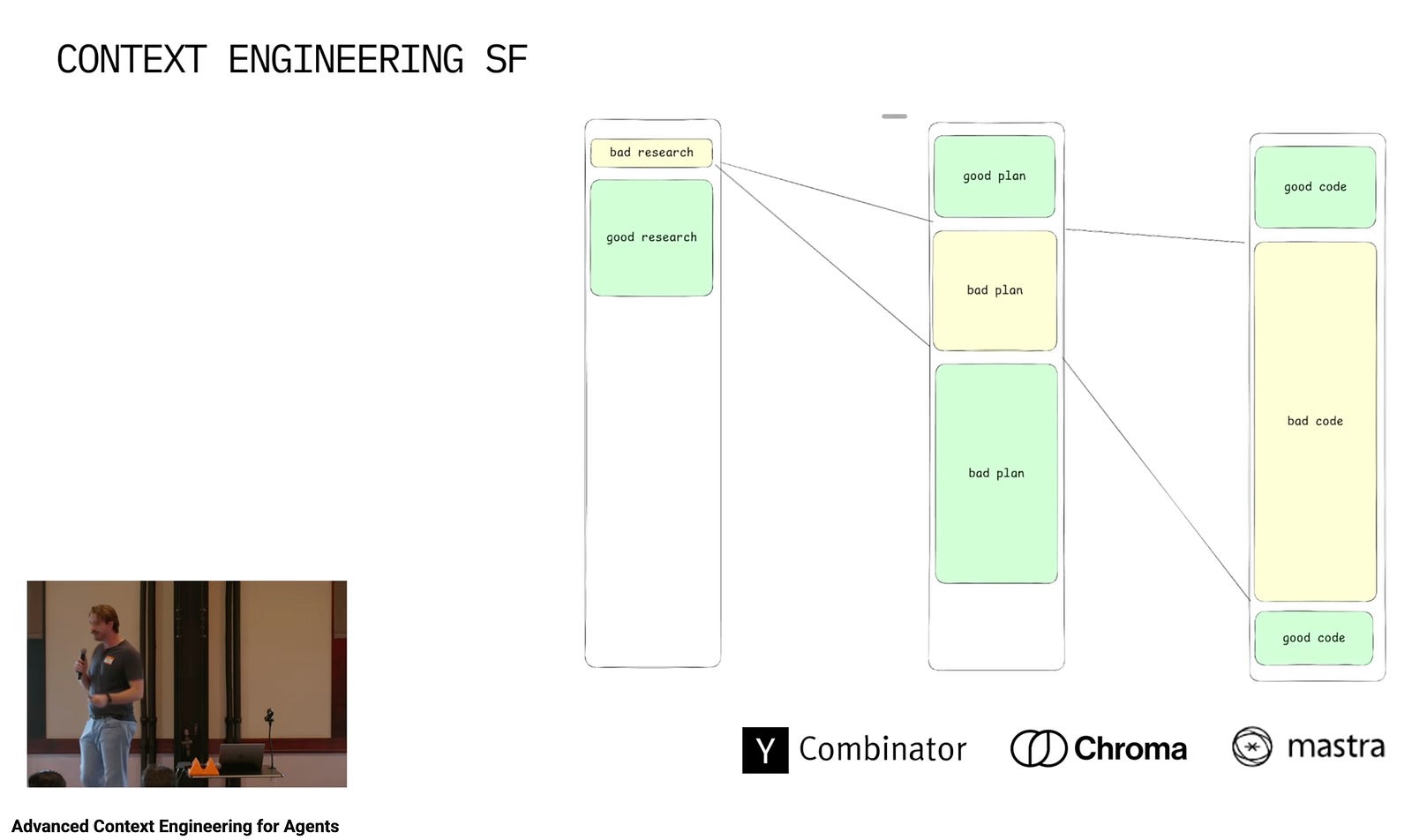
Another dimension is regarding how errors compound. Bad context does not produce uniformly mediocre output, it produces a cascade. A model that begins with a flawed understanding of your system will build a flawed plan on top of it, and then generate a large pile of code that faithfully executes that flawed plan. The mistake does not stay small. It ramifies. See the next image from a presentation that captures this phenomenon well.
Another dimension that has existed for a long time in general and is much less technical and more organisational is that tacit knowledge is obviously invisible to the model. And all orgs, teams, etc, have some degree of tribal/tacit knowledge. What lives only in a senior engineer's head, that could be anything from the reasons a particular abstraction exists, the constraints that shaped an API boundary, the incident that made the team distrust a certain pattern, etc. Writing it down is no longer just good practice for onboarding. It is how you convert institutional memory into something the agent can actually use.
That is where Part 1 ends , to wrap up, we talked about the models, the harnesses around them, and the context that feeds them. Three layers, each one a precondition for the next. Get the context wrong and the harness cannot save you. Get the harness wrong and the model’s raw capability doesn’t matter. And misread where the models actually sit ( their edges, their failure modes, the directions they are being pushed, etc.) and your mental model of the whole thing shaky and out of frame.
Part 2 will take a bit of a different angle. The question shifts from what are these tools doing to what does this mean for the engineer using them. Which skills compound over time and which atrophy quietly. What judgment still sits with humans and why handing it away is a specific kind of debt. And where, in a field drowning in noise, the actual signal lives.